Sequential API vs Functional API model in Keras
Keras is an open-source neural network library written in python. Keras allow us to easily build, train, evaluate and execute all sorts of neural networks. Keras was developed by François Chollet and was released in March 2015. It quickly gained popularity because Keras puts user experience front and center.

The core data structure of Keras is a model, which let us to organize and design layers. Sequential and Functional are two ways to build Keras models. Sequential model is simplest type of model, a linear stock of layers. If we need to build arbitrary graphs of layers, Keras functional API can do that for us.
we are going to build each of these models and explain difference. For this we need load dataset and make out models.
Keras provide some datasets, which can be loaded in using Keras directly. In this article, we will use the MNIST dataset of handwritten digits. It is 60,000 of 28x28 grayscale images of the 10 digits, along with a test set of 10,000 images.
Note that the dataset is already split into a training set, but there is no validation set, so we will create it now. Additionally, we must scale the input features. For that we dividing them by 255 which it convert them to floats as well:
this is some sample from the MNIST dataset:

Creating Sequential API model:
Sequential API is the easiest model to build and run in Keras. A sequential model allows us to create models layer by layer in a step by step fashion.
First of all we need to import from Keras models Sequential model.
After building model we can adding layers to this model.
In the first line we crate Sequential model. Next, we build the first layer and add it to the model. Next we add Dense hidden layer with 256 neurons. It will use ReLU activation function. Then we add a second Dense layer with 128 neurons with ReLU activation function as well. Finally, we add a Dense output layer with 10 neurons (one per class), using the softmax activation function.
Model’s summary() method display all the model layers, including each layers name, output shape of layers and number of parameters in each layer. This summary shows total number of parameters and number of trainable parameters and non-trainable parameters.
This is the result:

We can visualize the model:
Then:
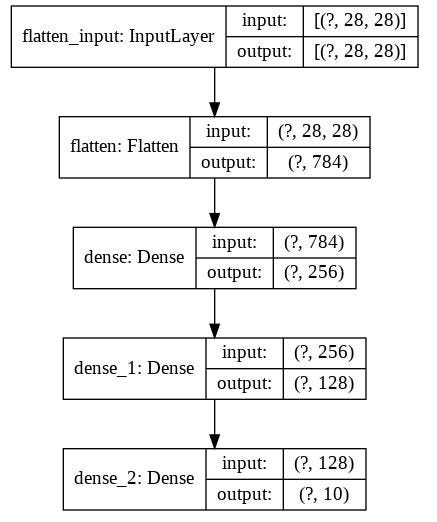
Now, after creating model we need to call its compile() method to specify the loss function and optimizer to use.
It is the time for training the model. For this we need just to call its fit() method.
Train on 55000 samples, validate on 5000 samples
Epoch 1/20
55000/55000 [==============================] - 6s 116us/sample - loss: 0.6153 - accuracy: 0.8461 - val_loss: 0.3118 - val_accuracy: 0.9114
Epoch 2/20
55000/55000 [==============================] - 6s 106us/sample - loss: 0.2913 - accuracy: 0.9180 - val_loss: 0.2419 - val_accuracy: 0.9350
Epoch 3/20
55000/55000 [==============================] - 6s 109us/sample - loss: 0.2383 - accuracy: 0.9323 - val_loss: 0.2118 - val_accuracy: 0.9394
Epoch 4/20
55000/55000 [==============================] - 6s 107us/sample - loss: 0.2053 - accuracy: 0.9420 - val_loss: 0.1829 - val_accuracy: 0.9500
Epoch 5/20
55000/55000 [==============================] - 6s 106us/sample - loss: 0.1808 - accuracy: 0.9484 - val_loss: 0.1633 - val_accuracy: 0.9562
Epoch 6/20
55000/55000 [==============================] - 6s 107us/sample - loss: 0.1610 - accuracy: 0.9545 - val_loss: 0.1503 - val_accuracy: 0.9588
Epoch 7/20
55000/55000 [==============================] - 6s 105us/sample - loss: 0.1453 - accuracy: 0.9597 - val_loss: 0.1361 - val_accuracy: 0.9640
Epoch 8/20
55000/55000 [==============================] - 6s 108us/sample - loss: 0.1317 - accuracy: 0.9629 - val_loss: 0.1310 - val_accuracy: 0.9644
Epoch 9/20
55000/55000 [==============================] - 6s 108us/sample - loss: 0.1201 - accuracy: 0.9661 - val_loss: 0.1206 - val_accuracy: 0.9680
Epoch 10/20
55000/55000 [==============================] - 6s 108us/sample - loss: 0.1102 - accuracy: 0.9695 - val_loss: 0.1147 - val_accuracy: 0.9690
Epoch 11/20
55000/55000 [==============================] - 6s 108us/sample - loss: 0.1015 - accuracy: 0.9717 - val_loss: 0.1082 - val_accuracy: 0.9712
Epoch 12/20
55000/55000 [==============================] - 6s 106us/sample - loss: 0.0940 - accuracy: 0.9742 - val_loss: 0.1029 - val_accuracy: 0.9720
Epoch 13/20
55000/55000 [==============================] - 6s 107us/sample - loss: 0.0871 - accuracy: 0.9760 - val_loss: 0.0989 - val_accuracy: 0.9728
Epoch 14/20
55000/55000 [==============================] - 6s 108us/sample - loss: 0.0812 - accuracy: 0.9777 - val_loss: 0.0943 - val_accuracy: 0.9742
Epoch 15/20
55000/55000 [==============================] - 6s 108us/sample - loss: 0.0752 - accuracy: 0.9791 - val_loss: 0.0919 - val_accuracy: 0.9750
Epoch 16/20
55000/55000 [==============================] - 6s 105us/sample - loss: 0.0703 - accuracy: 0.9805 - val_loss: 0.0882 - val_accuracy: 0.9758
Epoch 17/20
55000/55000 [==============================] - 6s 105us/sample - loss: 0.0660 - accuracy: 0.9824 - val_loss: 0.0847 - val_accuracy: 0.9762
Epoch 18/20
55000/55000 [==============================] - 6s 108us/sample - loss: 0.0616 - accuracy: 0.9835 - val_loss: 0.0837 - val_accuracy: 0.9774
Epoch 19/20
55000/55000 [==============================] - 6s 109us/sample - loss: 0.0576 - accuracy: 0.9843 - val_loss: 0.0817 - val_accuracy: 0.9786
Epoch 20/20
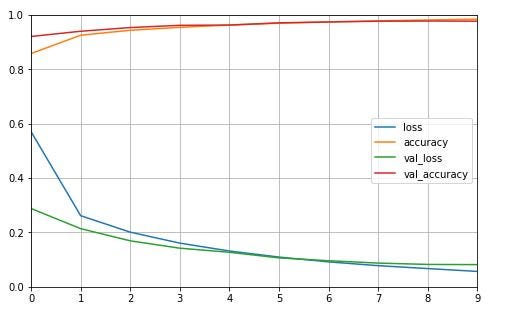
55000/55000 [==============================] - 6s 107us/sample - loss: 0.0541 - accuracy: 0.9858 - val_loss: 0.0801 - val_accuracy: 0.9782learning curve for this model is like this:

Sequential API is quite easy to use , but it is most limited. In Sequential API we can not create a model that:
- share layers
- have branches
- have multiple inputs
- have multiple output
Functional API solve this problem.
Creating Functional API model:
In Functional model, part or all of the inputs directly connected to the output layer. This architecture makes it possible for the neural network to learn both deep patterns and simple rules. let to build this model.
In first layer we need to create an Input object. After, flatten input objects then we add Dense layers with ReLU activation function. Then we need to reshape hidden layer output to concatenate with input layer. For build output layer we need to flatten concatenated layer. Output layer has 10 neuron with softmax activation function. Finally, we create Keras Model with inputs and outputs.
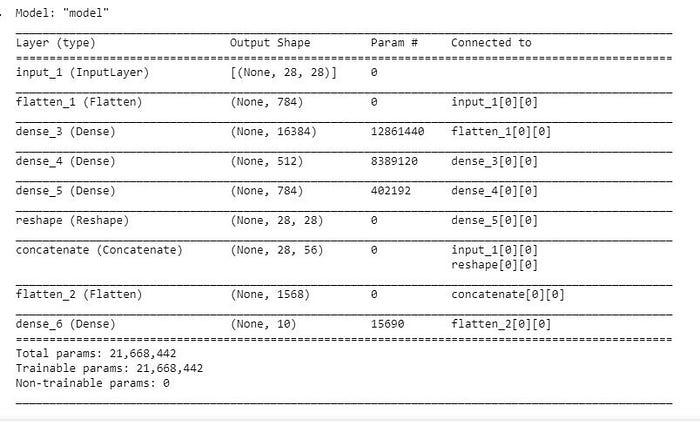
For this model summary is like this:
This is Functional model visualization:
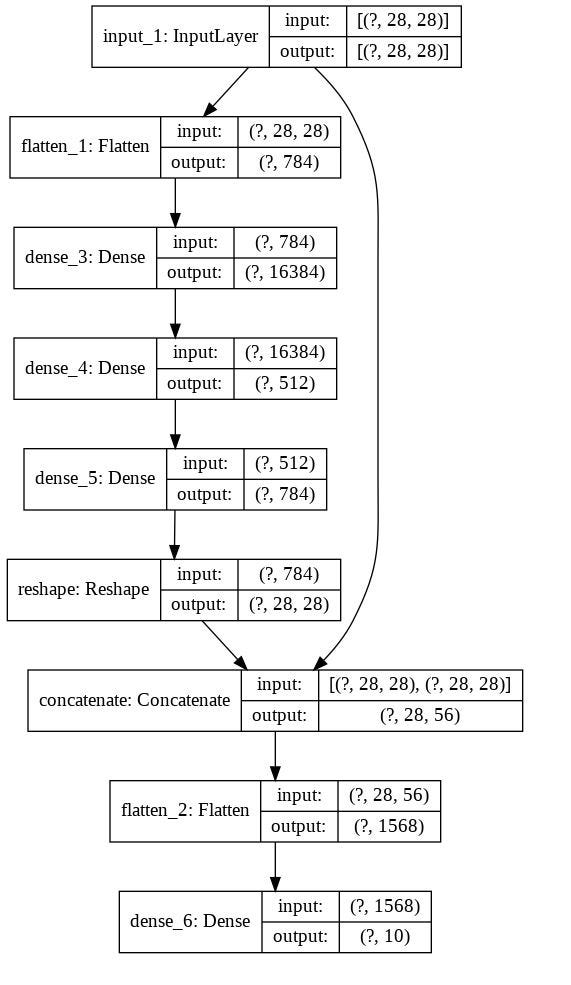
As you see in visualization part there is a by pass from input layer to concatenate layer which make it possible for neural network to learn through deep path and short pass.
After compile and fit the model, we have:
This is output:
Train on 55000 samples, validate on 5000 samples
Epoch 1/10
55000/55000 [==============================] - 216s 4ms/sample - loss: 0.5706 - accuracy: 0.8582 - val_loss: 0.2879 - val_accuracy: 0.9210
Epoch 2/10
55000/55000 [==============================] - 214s 4ms/sample - loss: 0.2616 - accuracy: 0.9256 - val_loss: 0.2139 - val_accuracy: 0.9402
Epoch 3/10
55000/55000 [==============================] - 214s 4ms/sample - loss: 0.2010 - accuracy: 0.9439 - val_loss: 0.1691 - val_accuracy: 0.9538
Epoch 4/10
55000/55000 [==============================] - 217s 4ms/sample - loss: 0.1606 - accuracy: 0.9546 - val_loss: 0.1420 - val_accuracy: 0.9620
Epoch 5/10
55000/55000 [==============================] - 214s 4ms/sample - loss: 0.1317 - accuracy: 0.9631 - val_loss: 0.1270 - val_accuracy: 0.9630
Epoch 6/10
55000/55000 [==============================] - 221s 4ms/sample - loss: 0.1094 - accuracy: 0.9697 - val_loss: 0.1063 - val_accuracy: 0.9712
Epoch 7/10
55000/55000 [==============================] - 220s 4ms/sample - loss: 0.0916 - accuracy: 0.9746 - val_loss: 0.0959 - val_accuracy: 0.9744
Epoch 8/10
55000/55000 [==============================] - 216s 4ms/sample - loss: 0.0778 - accuracy: 0.9784 - val_loss: 0.0872 - val_accuracy: 0.9772
Epoch 9/10
55000/55000 [==============================] - 215s 4ms/sample - loss: 0.0670 - accuracy: 0.9817 - val_loss: 0.0823 - val_accuracy: 0.9778
Epoch 10/10
55000/55000 [==============================] - 214s 4ms/sample - loss: 0.0566 - accuracy: 0.9847 - val_loss: 0.0816 - val_accuracy: 0.9772This is learning curve for Functional model:
For multiple inputs Functional model is perfect, for example if we want to send subset of input data through the wide path and other subset through the deep path. If we want to have multiple output again Functional model is perfect.
First we create inputs, after flatten input_A, Dense layers starts in the same time we have a deep patterns which connect input layer to concatenate layer. then with input_B concatenate with reshape layer and it build second branch with another output. Last line of code show how to build function model. As we have two input we should divide input X_train to two set as well as y_train. Because we have two output set.
and Functional model is like this:
The visualize of this model is like this:
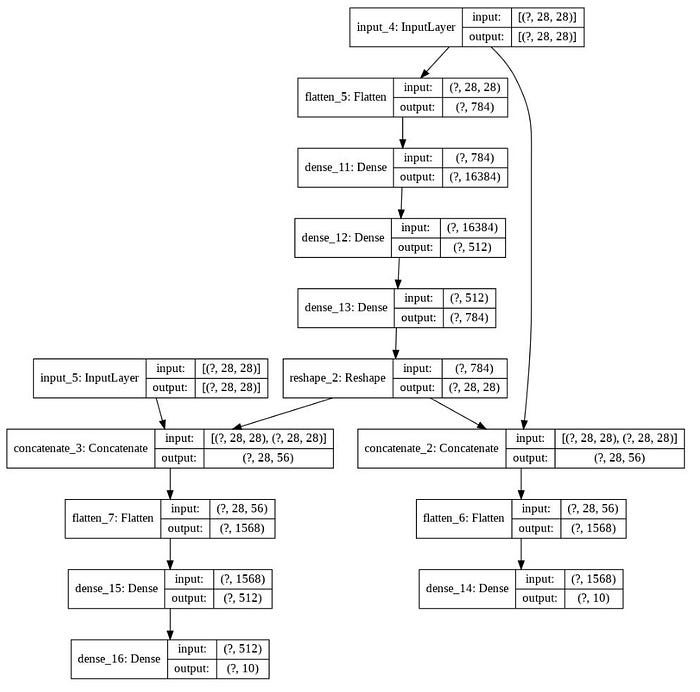
After compile and fit model we will have:
Train on 22000 samples, validate on 5500 samples
Epoch 1/10 22000/22000 [==============================] - 95s 4ms/sample - loss: 1.8279 - dense_14_loss: 0.8858 - dense_16_loss: 0.9415 - dense_14_accuracy: 0.7995 - dense_16_accuracy: 0.7801 - val_loss: 0.9718 - val_dense_14_loss: 0.5220 - val_dense_16_loss: 0.4498 - val_dense_14_accuracy: 0.8627 - val_dense_16_accuracy: 0.8907
Epoch 2/10 22000/22000 [==============================] - 94s 4ms/sample - loss: 0.8499 - dense_14_loss: 0.3948 - dense_16_loss: 0.4548 - dense_14_accuracy: 0.8945 - dense_16_accuracy: 0.8761 - val_loss: 0.7285 - val_dense_14_loss: 0.3893 - val_dense_16_loss: 0.3392 - val_dense_14_accuracy: 0.8842 - val_dense_16_accuracy: 0.9127
Epoch 3/10 22000/22000 [==============================] - 94s 4ms/sample - loss: 0.6937 - dense_14_loss: 0.3108 - dense_16_loss: 0.3830 - dense_14_accuracy: 0.9152 - dense_16_accuracy: 0.8920 - val_loss: 0.6440 - val_dense_14_loss: 0.3285 - val_dense_16_loss: 0.3154 - val_dense_14_accuracy: 0.9013 - val_dense_16_accuracy: 0.9100
Epoch 4/10 22000/22000 [==============================] - 94s 4ms/sample - loss: 0.6126 - dense_14_loss: 0.2657 - dense_16_loss: 0.3469 - dense_14_accuracy: 0.9265 - dense_16_accuracy: 0.9003 - val_loss: 0.5770 - val_dense_14_loss: 0.2895 - val_dense_16_loss: 0.2874 - val_dense_14_accuracy: 0.9093 - val_dense_16_accuracy: 0.9204
Epoch 5/10 22000/22000 [==============================] - 93s 4ms/sample - loss: 0.5555 - dense_14_loss: 0.2326 - dense_16_loss: 0.3229 - dense_14_accuracy: 0.9352 - dense_16_accuracy: 0.9075 - val_loss: 0.5361 - val_dense_14_loss: 0.2654 - val_dense_16_loss: 0.2705 - val_dense_14_accuracy: 0.9185 - val_dense_16_accuracy: 0.9244
Epoch 6/10 22000/22000 [==============================] - 93s 4ms/sample - loss: 0.5083 - dense_14_loss: 0.2058 - dense_16_loss: 0.3024 - dense_14_accuracy: 0.9429 - dense_16_accuracy: 0.9149 - val_loss: 0.5006 - val_dense_14_loss: 0.2401 - val_dense_16_loss: 0.2605 - val_dense_14_accuracy: 0.9295 - val_dense_16_accuracy: 0.9271
Epoch 7/10 22000/22000 [==============================] - 94s 4ms/sample - loss: 0.4691 - dense_14_loss: 0.1830 - dense_16_loss: 0.2865 - dense_14_accuracy: 0.9491 - dense_16_accuracy: 0.9191 - val_loss: 0.4862 - val_dense_14_loss: 0.2256 - val_dense_16_loss: 0.2605 - val_dense_14_accuracy: 0.9309 - val_dense_16_accuracy: 0.9231
Epoch 8/10 22000/22000 [==============================] - 94s 4ms/sample - loss: 0.4353 - dense_14_loss: 0.1631 - dense_16_loss: 0.2722 - dense_14_accuracy: 0.9540 - dense_16_accuracy: 0.9248 - val_loss: 0.4482 - val_dense_14_loss: 0.2082 - val_dense_16_loss: 0.2399 - val_dense_14_accuracy: 0.9344 - val_dense_16_accuracy: 0.9338
Epoch 9/10 22000/22000 [==============================] - 93s 4ms/sample - loss: 0.4053 - dense_14_loss: 0.1457 - dense_16_loss: 0.2597 - dense_14_accuracy: 0.9594 - dense_16_accuracy: 0.9260 - val_loss: 0.4290 - val_dense_14_loss: 0.1896 - val_dense_16_loss: 0.2393 - val_dense_14_accuracy: 0.9440 - val_dense_16_accuracy: 0.9322
Epoch 10/10 22000/22000 [==============================] - 94s 4ms/sample - loss: 0.3772 - dense_14_loss: 0.1304 - dense_16_loss: 0.2467 - dense_14_accuracy: 0.9636 - dense_16_accuracy: 0.9311 - val_loss: 0.4112 - val_dense_14_loss: 0.1813 - val_dense_16_loss: 0.2299 - val_dense_14_accuracy: 0.9449 - val_dense_16_accuracy: 0.9349Finally, this is learning curve for this model:
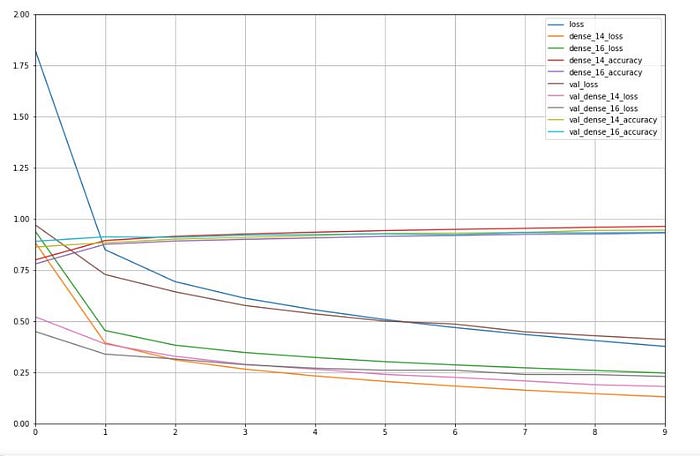
As you can see, we can build any sort of architecture we want easily with the Functional API.
